
When teams talk about cloud storage, amazon s3 is usually the first name that comes up – and for good reason. Amazon Simple Storage Service (Amazon S3) is an object storage service offering industry-leading scalability, data availability, security, and performance. Also known as s3 storage, it is not just a place to dump files.
Amazon S3 is a massively scalable storage service designed to balance performance, security, and cost when used intelligently, and is recognized for its industry leading scalability. In this guide, we go beyond the basics and explore advanced strategies that help you optimize amazon s3 for both cost efficiency and high performance without sacrificing reliability.
What Is Amazon S3 and Why It Still Dominates Object Storage
Amazon S3, also known as amazon simple storage service, is an object storage service that stores data as objects within buckets. Each object includes the data itself, metadata, and a unique key. Unlike traditional file storage or block-based systems, amazon s3 does not require you to provision capacity in advance, making it a fully elastic and massively scalable storage service. An aws account is required to create and manage S3 buckets, serving as the foundational element for accessing and configuring AWS services like Amazon S3.
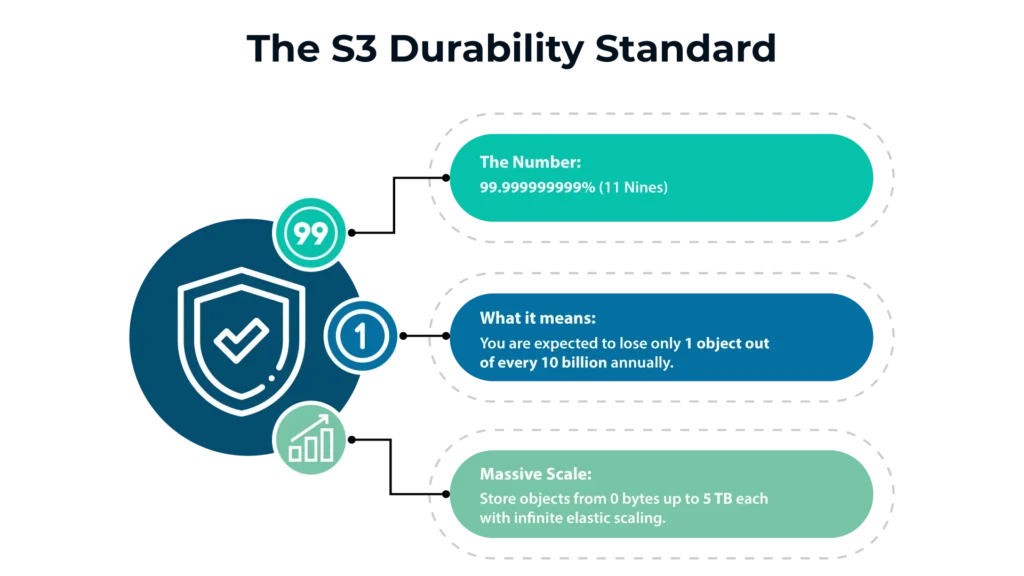
From startups to global enterprises, organizations rely on amazon s3 to store everything from application logs to critical data. AWS reports that the platform delivers 99.999999999% data durability, meaning only one object is expected to be lost out of every 10 billion objects stored annually.
Customers of all sizes and industries use Amazon S3 for a wide range of use cases, such as data lakes, cloud-native applications, and mobile apps. That level of resilience is one of the strongest reasons amazon s3 remains a cornerstone of modern cloud architectures.
Understanding Buckets, Objects, and Regions
An s3 bucket acts as a container for objects. To store data, you first create an s3 bucket, assign a globally unique name, and select an aws region. Choosing the right aws region is not just a compliance decision; it directly affects latency, performance, and even cost. Amazon S3 stores data redundantly across multiple data centers to ensure availability and resilience.
Each object stored inside an s3 bucket has a key that acts as its unique identifier. Amazon S3 stores data as objects within buckets, where each object consists of a file and its metadata. Objects can be up to 5 TB in size, enabling organizations to manage structured and unstructured data at scale. Data can also be stored in a specific data center location by selecting the appropriate aws region, helping meet data residency and regulatory requirements.
Amazon S3 vs Traditional File and Block Storage
While amazon s3 is an object storage solution, services like amazon elastic file system and Amazon EBS fall under file system and block storage categories. The difference matters when optimizing cost and performance.
Amazon S3 is not attached to a virtual machine, unlike EBS. This design allows amazon s3 to scale independently and serve use cases such as data lakes, backups, and big data analytics. Because objects can be queried directly, amazon s3 is frequently used as the backbone for data lakes and analytics platforms, where flexibility and scale are critical.
Storage Classes: The Foundation of Cost Optimization
One of the most powerful optimization levers in amazon s3 is its wide range of storage classes. These classes allow you to align storage costs with real-world access patterns.
- Standard storage for frequently accessed data
- Infrequent Access for infrequently accessed data
- Archive tiers such as Glacier and deep archive for long-term retention
AWS estimates that organizations can reduce costs by 30% to 70% by moving older or less accessed data into cost effective storage classes. Using lifecycle policies, amazon s3 automatically shifts objects stored between storage tiers, helping you manage data without manual effort.
Lifecycle Management and Intelligent Tiering
Lifecycle management is where amazon s3 truly helps eliminate operational complexities. Policies can automatically transition data from standard storage to archive data tiers or even delete obsolete files. Amazon S3 supports multiple versions of objects within a bucket, enabling version control and restoration of previous file states to prevent data loss or overwriting.
For example, log files can move to archive data tiers after 30 days and then into deep archive after 180 days. This approach significantly reduces storage usage while maintaining compliance and data protection.
Metrics show that enterprises using lifecycle automation reduce manual storage management tasks by over 60%, freeing teams to focus on higher-value initiatives.
Organizations also use Amazon S3 to archive data at a lower cost by utilizing S3 Glacier storage classes.
Performance Optimization for Latency-Sensitive Workloads
Not all workloads are the same. Latency sensitive applications require low access times, and amazon s3 supports this through regional placement and optimized access methods for high-performance, scalable, and secure data storage.
Storing data in the closest aws region reduces network hops, improving response times for accessed data. Using multiple availability zones, amazon s3 ensures consistent data availability while delivering high throughput.
For analytics-heavy workloads, amazon s3 integrates seamlessly with AWS analytics tools, making it ideal for big data analytics and real-time insights.
Security, Encryption, and Data Protection by Design
Security is built into amazon s3 at multiple levels. All s3 bucket configurations are private by default, ensuring public access is blocked unless explicitly enabled.
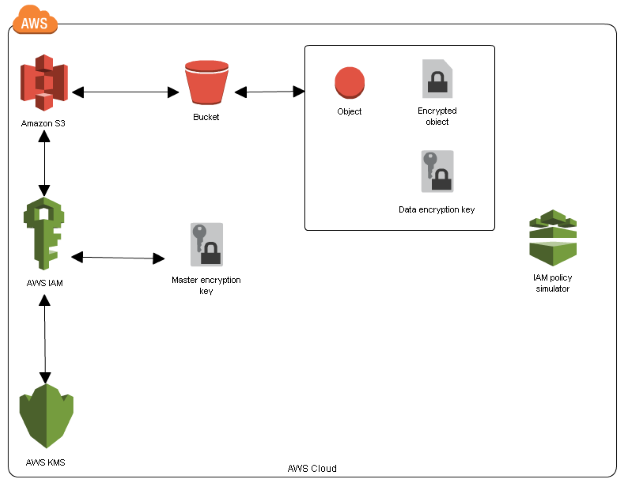
Amazon S3 supports encryption both at rest and in transit, and administrators can encrypt data before uploading it. Fine-grained permissions are enforced through IAM policies, access control lists, and fine tuned access controls.
Advanced features like Object Lock enforce Write Once, Read Many (WORM) policies, supporting regulatory compliance. Amazon S3 is compliant with PCI DSS and HIPAA, making it suitable for handling credit card and healthcare data when configured correctly.
Access Management and Monitoring Integration
Effective access management ensures only authorized users can interact with your data. Amazon s3 allows you to control access through bucket policies, IAM roles, and access point configurations.
Integration with AWS services such as CloudTrail, CloudWatch, and Macie enables monitoring, auditing, and anomaly detection. Organizations using these integrations report up to 40% faster incident response times, strengthening overall data protection protect strategies.
Using Amazon S3 for Disaster Recovery and Backups
Amazon s3 is widely used for disaster recovery and storing backups due to its durability and multi-region capabilities. Replication features allow data to be copied across multiple locations, ensuring business continuity.
For enterprises managing critical data, cross-region replication reduces recovery point objectives and supports compliance mandates. This makes amazon s3 a preferred choice for long-term data archives and resilient backup strategies.
Cost Forecasting and the Reality of S3 Pricing
While amazon s3 offers flexible pricing, forecasting costs can be challenging. Charges apply for storage per gigabyte, API requests, and data ingress or egress. API calls are billed in fractions of a cent per 1,000 requests, which can add up at scale.
AWS provides a pricing calculator to estimate costs, but new applications often struggle with accurate forecasts. Understanding how much data you store, how often it is accessed, and which storage services are used is essential for predictable spending.
Advanced Use Cases: Data Lakes, Analytics, and AI
Modern organizations use amazon s3 as the foundation for data lakes, enabling storage of structured and unstructured data at scale. This design supports analytics, machine learning, and generative AI workloads.
In fact, many AI-driven applications rely on amazon s3 to collect training data, manage data, and serve insights across multiple devices. AWS reports that analytics workloads built on amazon s3 scale up to 10x faster compared to traditional on-prem storage systems.
Hosting Static Websites and Content Delivery
Beyond analytics, amazon s3 supports hosting static websites, media distribution, and software downloads. With proper configuration, teams can deliver high availability content globally while keeping storage costs low.
Users can manage their cookie preferences, including the option to decline performance cookies, which are used to collect anonymous analytics for site improvements.
Combined with access logging and analytics, organizations can collect anonymous statistics, display relevant content, and even deliver relevant marketing content efficiently.
How to Use an S3 Bucket in AWS Management Console
Using the aws management console, you can create an s3 bucket, define policies, upload objects, and configure lifecycle rules through a web based user interface. The process is straightforward, yet powerful enough to support enterprise-grade requirements.
Administrators can upload objects, set permissions, enable block public access, and monitor storage usage in real time. This simplicity is one reason amazon s3 continues to outperform alternative storage services such as google cloud storage in adoption metrics.
Final Thoughts: Making Amazon S3 Work Smarter for You
Amazon s3 is far more than a simple storage solution. When optimized correctly, it helps organizations reduce costs, improve performance, and strengthen security – all while scaling effortlessly.
With intelligent use of storage classes, lifecycle policies, encryption, and access controls, teams can transform amazon s3 into a strategic asset. Whether you are managing data lakes, archiving data, or supporting analytics at scale, amazon s3 offers the flexibility and reliability needed to stay competitive in modern cloud computing environments.
Optimize Amazon S3 Smarter with Cloudeva.ai
Managing Amazon S3 at scale often means juggling storage classes, controlling storage costs, securing critical data, and keeping performance predictable across regions. Cloudeva.ai simplifies this complexity with an AI-first, unified view of your S3 environment – helping you analyze storage usage, optimize access tiers, enforce fine-tuned access controls, and proactively reduce spend.
If you want to eliminate operational complexities, improve visibility across buckets, and make data-driven decisions for cost and performance optimization, explore how Cloudeva.ai can turn your Amazon S3 strategy into a competitive advantage.
Keynote Summary: Amazon S3 is a massively scalable object storage service that balances performance, cost, and security when used intelligently. The real optimization lever is storage class selection – moving data across Standard, Infrequent Access, and Glacier tiers can reduce costs by 30–70%. Lifecycle policies, Intelligent Tiering, and multipart uploads automate this without manual effort.
FAQs:
What is Amazon S3?
An object storage service by AWS that stores data as objects in buckets with 99.999999999% durability.
How do I reduce S3 costs?
Use lifecycle policies to auto-transition data to lower-cost storage classes based on access frequency.
What is S3 Intelligent Tiering?
A storage class that automatically moves objects between tiers based on access patterns without retrieval fees.
How is S3 different from EBS?
S3 is object storage not attached to a VM; EBS is block storage tied to a specific EC2 instance.
What are S3 storage classes?
Standard, Standard-IA, One Zone-IA, Glacier Instant Retrieval, Glacier Flexible Retrieval, and Glacier Deep Archive.