How Cloudeva.ai Turns Cloud Noise into Governed Outcomes
Every cloud environment is a high-decibel neighbor. Costs shift. Configurations drift. Resources blink in and out of existence like neon signs. For the modern CTO, managing this isn’t just a technical challenge; it’s a cognitive one.
The volume of data points coming out of AWS, Azure, and GCP isn’t just high – it’s overwhelming. Most organizations have invested heavily in ‘observability’ and ‘monitoring,’ yet they find themselves more blind than ever to the actual state of their governance.
The core problem is simple but devastating, catching a ball isn’t the same as knowing where to throw it. We have mastered the art of the ‘Signal’ (the alert, the spike, the vulnerability), but we have failed to build a bridge to the ‘Outcome.’
The gap between a detected change and a confident, governed response is where cloud operations break down. Teams escalate. Tickets pile up. Slack channels become graveyard for unaddressed alerts. By the time someone actually makes a call, the context has evaporated. The engineer who launched the resource is on another project; the budget owner is in a meeting; the security risk has already been exploited.
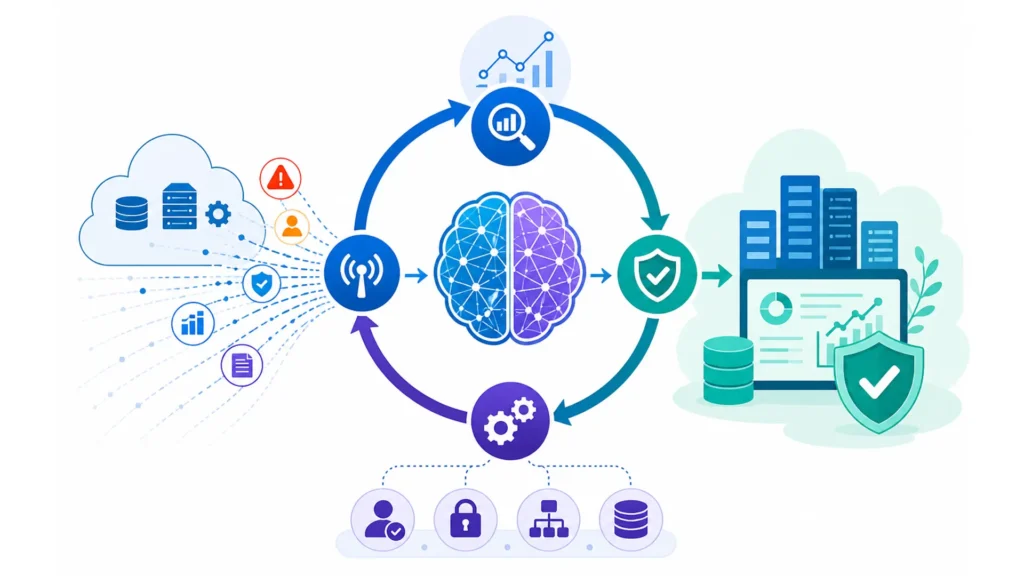
Cloudeva.ai was built around a singular, transformative idea: The Signal-to-Decision Loop. We aren’t building a detection pipeline or an alert chain. We are building a closed-loop system that takes raw operational chaos and refines it into a decision-ready output: with context, evidence, and policy already applied. This is the blueprint for a self-tightening cloud architecture.
1. The Taxonomy of Cloud Noise: Why Alerts are Failing You
To understand why a loop is necessary, we must first look at the failure of the linear alert model. Cloud environments produce thousands of data points a day. A spike in EC2 spend, an S3 bucket left open, a tag policy exception, an underutilized reserved instance – on the surface, these look like distinct events. In reality, they are symptoms of a single operational state.
Most tools surface these as ‘Alerts.’ The word itself is part of the problem. An alert implies immediate action is required, yet 90% of cloud alerts are informational or false positives. This creates a boy-who-cried-wolf scenario that leads to ‘Alert Fatigue.’ When everything is a priority, nothing is.
For a CTO, alert fatigue isn’t just a productivity drain; it’s a massive hidden risk. It represents the probability that a critical governance failure – like a wide-open security group or a $50k cost spike, will be buried under a mountain of trivial notifications about ‘minor tagging inconsistencies.’
The smarter response isn’t more alerts. It’s better loops. We need to move from ‘I see something happened’ to ‘I know what to do about it.’
2. The Mechanics: How the Signal-to-Decision Loop Operates
Stage 1: Signal (The Intelligent Filter)
At Cloudeva.ai, the loop starts with ingestion, but it immediately moves to correlation. We don’t just pass through every API call from CloudTrail or every line item from your CUR. Our AI layer applies deduplication and cross-provider correlation.
If a cost spike in AWS is related to a configuration change in Azure, they are merged into a single operational ‘Signal.’ We filter the noise so that only meaningful, high-fidelity signals reach the next stage. One change doesn’t mean one alert for every stakeholder; it means one interpreted signal, routed to the one person who can actually influence the outcome.
Stage 2: Context (The Semantic Enrichment)
Raw signals don’t carry meaning. ‘EC2 Instance i-04f… is over budget’ is a signal. ‘EC2 Instance i-04f…, which belongs to the Phoenix Project, managed by Jane Doe, has exceeded its monthly forecasted budget by 22% due to an unoptimized GPU workload’ is context.
Cloudeva.ai enriches signals with metadata, ownership records, and historical policy performance. We answer the ‘Who,’ ‘Where,’ and ‘Why’ before the operator even opens the ticket. This removes the ‘investigation phase’ that usually eats up 70% of an engineer’s response time.
Stage 3: Decision (The Eva Advisor and the EVA Model)
This is the heart of the platform. Using our Eva Advisor, we present the signal through the EVA model: Explain, Verify, Advise.
1) Explain: What is happening in plain English?
2) Verify: What evidence do we have (logs, charts, policy docs)?
3) Advise: What is the recommended course of action based on your specific governance posture?
Crucially, Cloudeva.ai operates on a read-only architecture. We do not ‘auto-remediate’ and risk breaking your production environment. We provide the intelligence for a human-led, governed decision. The human makes the call; the system provides the conviction.
Stage 4: Outcome (The Feedback Mechanism)
The loop doesn’t end when a button is clicked. The decision – whether to approve, ignore, or escalate – is logged as a ‘Governed Outcome.’ This outcome is fed back into the AI engine. If a specific type of cost spike is consistently marked as an ‘approved exception’ for a specific dev team, the system learns.
It adjusts the sensitivity of that signal. This is the ‘Self-Tightening’ mechanism. Your governance isn’t a static document; it’s a living, breathing logic that evolves with your business.
3. The Architecture of Trust: Why CTOs Fear the Black Box
Many ‘Cloud Management Platforms’ (CMPs) promise auto-remediation. They want to be the ‘autopilot’ for your cloud. But for a CTO at an enterprise level, ‘autopilot’ is terrifying. A script that automatically shuts down an ‘underutilized’ instance might accidentally kill a legacy heartbeat service that isn’t reflected in modern tagging schemas.
Cloudeva.ai optimizes for the middle – the decision layer. We believe that cloud governance should be human-led but AI-assisted. By keeping the human in the loop, we ensure that tribal knowledge – the stuff that isn’t in the code, is still part of the decision-making process. The Decision Queue is our way of surfacing these choices in a ranked, prioritized, and evidence-backed interface.
This creates an ‘Architecture of Trust.’ Engineers trust the tool because it doesn’t do things behind their back. Management trusts the tool because every action taken has a clear audit trail linked to a specific governance policy.
4. Practical Impact: The Self-Tightening Effect
What happens after six months of using a Signal-to-Decision Loop? The ‘Self-Tightening’ effect begins to take hold. In most organizations, cloud waste and risk grow linearly with cloud spend. With Cloudeva.ai, the relationship is decoupled.
As the loop learns from your outcomes, your ‘Decision Queue’ actually gets shorter over time. Not because there’s less activity in your cloud, but because the system has become an expert in your specific organizational nuances. It stops bothering you with things it knows are ‘business as usual’ and gets laser-focused on the genuine anomalies.
For the CTO, this means shifting the team’s focus from ‘Keeping the Lights On’ (KTLO) to ‘Innovation.’ You stop paying your most expensive engineers to be ‘cloud janitors’ who clean up tagging errors and start letting them be ‘cloud architects’ who build for scale.
Conclusion: Closing the Loop
The era of ‘finding things’ is over. We have enough scanners. We have enough dashboards. What we lack is a system of action that respects the complexity of the modern enterprise. Cloudeva.ai’s Signal-to-Decision Loop is that system.
It transforms the chaotic, noisy reality of multi-cloud management into a streamlined, governed, and predictable operational flow. It turns ‘What happened?’ into ‘What’s next?‘
If you’re ready to see what your cloud looks like when the noise stops and the decisions start, it’s time to try the Decision Queue.
Appendix: The EVA Model Deep Dive
The EVA model is the pedagogical foundation of the Cloudeva interface. EXPLAIN: The explanation layer uses Large Language Models trained on cloud infrastructure patterns to translate JSON blobs into narrative context. VERIFY: The verification layer provides the ‘receipts.’ It links directly to the specific cloud resource, the policy it violated, and the historical trend line. ADVISE: The advice layer is the most sophisticated. It looks at the cost of action vs. the cost of inaction. By providing these three pillars, we eliminate the ‘context switching’ that traditionally happens when an engineer has to move between a monitoring tool, a cloud console, and a documentation wiki.